原型模式
引言
原型模式相对来说比较简单,可能听着比较陌生,事实上工作中用的也不多,面试也较少提及,但是在一些底层源码中经常能看到它的身影。
原型模式内容不多,但是我会引申出一些相关联的知识,希望能耐心看下去。
在正式开始介绍原型模式之前,我们先来看一个案例。
模拟场景
假设有一个班级类,其属性结构如下:
public class Class {
private int classNo; // 班级编号
private String className; // 班级名称
private Student student; // 学生对象
public Class(int classNo, String className, Student student) {
this.classNo = classNo;
this.className = className;
this.student = student;
}
// 省略get/set/toString方法
}
public class Student {
private String name; // 姓名
private int age; // 年龄
public Student(String name, int age) {
this.name = name;
this.age = age;
}
// 省略get/set/toString方法
}在客户端中创建了一个原型对象
public class Client {
public static void main(String[] args) {
Student student = new Student("张三", 20);
// 班级对象
Class clazz = new Class(1, "追梦班", student);
System.out.println(clazz);
}
}输出结果:
Class{classNo=1, className='追梦班', student=Student{name='张三', age=20}}客户需求
此时客户端需要一个和班级对象clazz完全相同的一个对象,我们常规的做法就是使用new关键字创建一个新对象,然后挨个给属性赋值,思考一下这样做有什么问题?
我们上面的案例相对来说比较简单,但是如果这是个大对象,或者其中的某个属性是通过大量的数据库操作才得来的,使用new的方式显然不太好,代码冗余不说,效率也极低。
那么有什么好的方式来实现这个需求呢?那就是克隆,直接把整个对象拷贝一份。这也是原型模式的核心思想。
原型模式
基本概念
原型模式(Prototype Pattern)也叫克隆模式,用于创建重复的对象,同时又能保证性能。被克隆的类就叫原型类。
原型模式属于创建型模式,就是根据一个对象再创建另外一个可定制的对象,而且不需要知道任何创建的细节。
原型模式的主要思想基于现有的对象克隆出一个新的对象,一般是由对象的内部提供克隆的方法。
实现方式
- 实现标记型接口
Cloneable
在Java语言中有一个Cloneable接口,他的作用只有一个,就是在运行时通知虚拟机可以安全地在实现了此接口的类上使用clone方法。在Java虚拟机中,只有实现了这个接口的类才可以被拷贝。
- 重写Object类中的
clone方法
Object类中的clone方法,作用是返回对象的一个拷贝,但其作用域是protected类型的,一般的类无法调用,因此原型类需要将clone方法的作用域修改为public类型。
注意:
- 如果只是重写clone方法,而没实现接口,调用时会抛出CloneNotSupportedException异常;
- clone方法是一个本地方法,它的底层是用c++直接操作内存,效率极高。
代码实现
我们知道了如何实现原型模式,接下来对上述案例进行优化。
- Class类实现Cloneable接口,并重写clone方法。
public class Class implements Cloneable {
// 此处省略一万行代码...
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}- 在客户端尝试克隆一个新对象。
public class Client {
public static void main(String[] args) throws CloneNotSupportedException {
Student student = new Student("张三", 20);
// 原型对象
Class clazz = new Class(1, "追梦班", student);
System.out.println(clazz);
// 克隆出来的具体对象
Class cloneClass = (Class)clazz.clone();
System.out.println(cloneClass);
}
}输出结果:
Class{classNo=1, className='追梦班', student=Student{name='张三', age=20}}
Class{classNo=1, className='追梦班', student=Student{name='张三', age=20}}哦吼,貌似已经实现了,是不是感觉很简单?No,真正的坑才刚刚开始。我们修改一下克隆出来的学生名称,打印一下两个对象的属性值:
public class Client {
public static void main(String[] args) throws CloneNotSupportedException {
Student student = new Student("张三", 20);
// 原型对象
Class clazz = new Class(1, "追梦班", student);
System.out.println("===修改属性之前===");
System.out.println(clazz);
// 克隆出来的具体对象
Class cloneClass = (Class)clazz.clone();
System.out.println(cloneClass);
// 修改克隆出来的对象的学生名称
cloneClass.getStudent().setName("李四");
System.out.println("===修改属性之后===");
System.out.println(clazz);
System.out.println(cloneClass);
}
}输出结果:
===修改属性之前===
Class{classNo=1, className='追梦班', student=Student{name='张三', age=20}}
Class{classNo=1, className='追梦班', student=Student{name='张三', age=20}}
===修改属性之后===
Class{classNo=1, className='追梦班', student=Student{name='李四', age=20}}
Class{classNo=1, className='追梦班', student=Student{name='李四', age=20}}发现问题没有?原来的对象clazz学生姓名也被修改了!这就是浅克隆。
浅克隆
基本概念
浅克隆(Shadow Clone)是把原型对象中成员变量为值类型的属性都复制给克隆对象,把原型对象中成员变量为引用类型的引用地址也复制给克隆对象,也就是原型对象中如果有成员变量为引用对象,则此引用对象的地址是共享给原型对象和克隆对象的。
原理分析
上述情况是怎么造成的,我们来讨论一下。
首先我们得达成一个共识,一个类中的属性分为基本数据类型和引用数据类型,基本数据类型存放的就是具体的数值,而引用类型存放的是对象的引用,而不是存放的对象。这一点很重要,也是很多人的一个误区。
当我们克隆student对象时,其实只是克隆了student对象的引用,并没有真正克隆一个新的student对象,不知道大家能不能理解,看下图:

这样其实就能理解为什么我们修改了cloneClass对象的学生姓名以后,原型对象clazz的学生姓名也被修改了,因为大家其实还是用的同一个对象。
了解了浅克隆的问题,那么如何解决呢?那就得用深克隆了。
深克隆
基本概念
深克隆(Deep Clone)是将原型对象中的所有类型,无论是值类型还是引用类型,都复制一份给克隆对象,也就是说深克隆会把原型对象和原型对象所引用的对象,都复制一份给克隆对象。
原理分析
明白了浅克隆存在的问题,其实就好理解深克隆了。既然克隆对象的引用不行,那我就把引用的对象也克隆一份就好了,如下图所示:
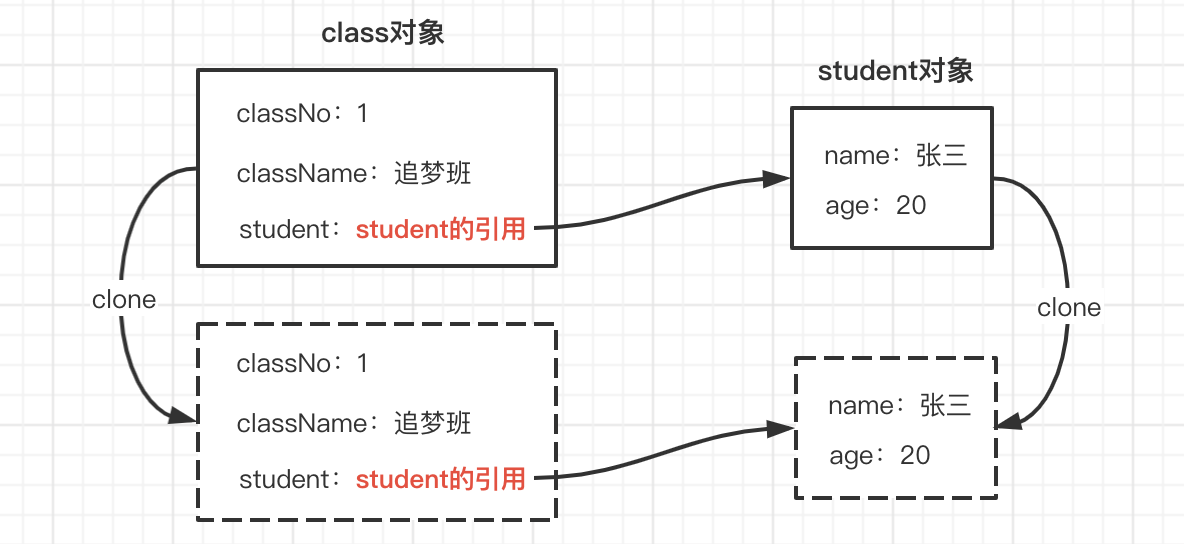
到这儿应该彻底明白深克隆和浅克隆了吧。如果觉得我讲的还不错,记得帮我点个赞(^_^)v
深克隆的实现方式
- 改造clone方法
这种方式就是将所有的引用对象都克隆一遍。既然想要克隆引用对象,那么引用对象也要符合克隆的条件,即实现Cloneable接口,重写clone方法。然后将克隆对象的引用地址指向新的引用对象(这段话如果不懂也没关系,下面一看代码立马就清楚了)。
- 使用序列化(不推荐)
这种方式是比较有争议的方式,你从网上搜深克隆的实现方式,肯定有一堆人会提到这个,但其实是不对的。下面谈一下我的理解:
序列化从本质上来讲跟克隆没有半毛钱的关系,序列化是序列化当前对象,它不需要克隆新对象。使用这种方式的只是利用了序列化和反序列化的特点,间接的实现了对象的克隆。而且提到序列化,肯定就涉及到了IO,那么和clone相比,效率一下就降低了,要知道,克隆可是内存的拷贝,所以说个人不太推荐这种方式。
代码实现
- 将引用对象student改造一下。
public class Student implements Cloneable {
// 此处省略一万行代码...
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}- 改造一下原型类的clone方法。
@Override
public Object clone() throws CloneNotSupportedException {
Class clazz = (Class)super.clone();
clazz.student = (Student) this.student.clone();
return clazz;
}- 客户端测试结果如下:
===修改属性之前===
Class{classNo=1, className='追梦班', student=Student{name='张三', age=20}}
Class{classNo=1, className='追梦班', student=Student{name='张三', age=20}}
===修改属性之后===
Class{classNo=1, className='追梦班', student=Student{name='张三', age=20}}
Class{classNo=1, className='追梦班', student=Student{name='李四', age=20}}可以清楚的看到,当我们修改了引用对象student的姓名之后,原型对象未发生改变,深克隆实现成功!
缺点
这种方式的主要缺陷是每一个抽象原型的子类都必须实现clone操作,实现clone函数可能会很困难。当所考虑的类已经存在时就难以新增clone操作,当内部包括一些不支持克隆或有循环引用的对象时,实现克隆可能也会很困难的。这可能也是为什么会有人用序列化去实现深克隆。
扩展知识
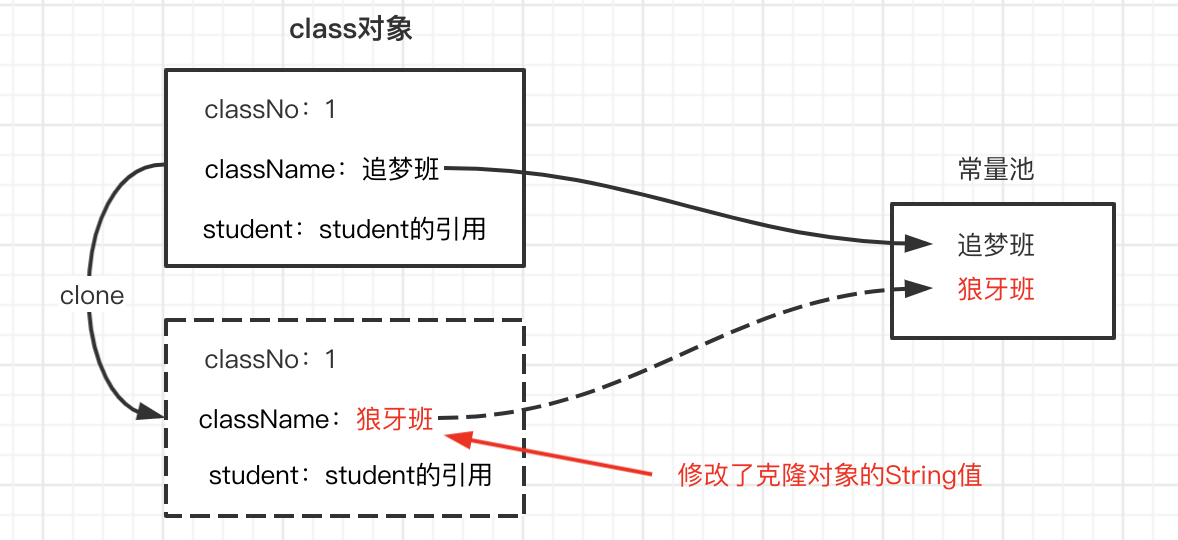
我们一直在说,浅克隆只能克隆基本数据类型,引用类型是需要进行深克隆的,那么String需要进行深克隆吗?
不需要,因为String虽然是引用类型,但是它的值是存在常量池中的,常量池本身就是共享的。如果我们克隆的对象更改了值,在常量池中其实是生成一个新的值(String是不可变的),那么它的引用会直接指向常量池中新的值,而不会影响原型对象的值,所以不需要对String进行深克隆,如图所示:
有态度的总结
- 原型模式就是对象的复制,主要使用Object类下的clone方法实现,而且一定要实现Cloneable接口;
- 深克隆与浅克隆的问题中,会发生深克隆的有Java中的8种基本类型以及它们的包装类型,另外还有String类型,其余的都是浅克隆。
好了,原型模式就讲到这里了,咱们下期见~
本博客所有文章均为原创,转载请注明出处!